



|
|
|
|
|
The goal of this book is to teach you to think like a computer scientist. I like the way computer scientists think because they combine some of the best features of Mathematics, Engineering, and Natural Science. Like mathematicians, computer scientists use formal languages to denote ideas (specifically computations). Like engineers, they design things, assembling components into systems and evaluating tradeoffs among alternatives. Like scientists, they observe the behavior of complex systems, form hypotheses, and test predictions.
The single most important skill for a computer scientist is problem-solving. By that I mean the ability to formulate problems, think creatively about solutions, and express a solution clearly and accurately. As it turns out, the process of learning to program is an excellent opportunity to practice problem-solving skills. That's why this chapter is called "The way of the program."
Of course, the other goal of this book is to prepare you for the Computer Science AP Exam. We may not take the most direct approach to that goal, though. For example, there are not many exercises in this book that are similar to the AP questions. On the other hand, if you understand the concepts in this book, along with the details of programming in C++, you will have all the tools you need to do well on the exam.
The programming language you will be learning is C++, because that is the language the AP exam is based on, as of 1998. Before that, the exam used Pascal. Both C++ and Pascal are high-level languages; other high-level languages you might have heard of are Java, C and FORTRAN.
As you might infer from the name "high-level language," there are also low-level languages, sometimes referred to as machine language or assembly language. Loosely-speaking, computers can only execute programs written in low-level languages. Thus, programs written in a high-level language have to be translated before they can run. This translation takes some time, which is a small disadvantage of high-level languages.
But the advantages are enormous. First, it is much easier to program in a high-level language; by "easier" I mean that the program takes less time to write, it's shorter and easier to read, and it's more likely to be correct. Secondly, high-level languages are portable, meaning that they can run on different kinds of computers with few or no modifications. Low-level programs can only run on one kind of computer, and have to be rewritten to run on another.
Due to these advantages, almost all programs are written in high-level languages. Low-level languages are only used for a few special applications.
There are two ways to translate a program; interpreting or compiling. An interpreter is a program that reads a high-level program and does what it says. In effect, it translates the program line-by-line, alternately reading lines and carrying out commands.
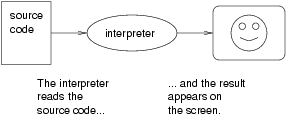
A compiler is a program that reads a high-level program and translates it all at once, before executing any of the commands. Often you compile the program as a separate step, and then execute the compiled code later. In this case, the high-level program is called the source code, and the translated program is called the object code or the executable.
As an example, suppose you write a program in C++. You might use a text editor to write the program (a text editor is a simple word processor). When the program is finished, you might save it in a file named program.cpp, where "program" is an arbitrary name you make up, and the suffix .cpp is a convention that indicates that the file contains C++ source code.
Then, depending on what your programming environment is like, you might leave the text editor and run the compiler. The compiler would read your source code, translate it, and create a new file named program.o to contain the object code, or program.exe to contain the executable.
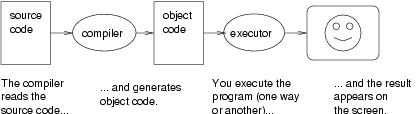
The next step is to run the program, which requires some kind of executor. The role of the executor is to load the program (copy it from disk into memory) and make the computer start executing the program.
Although this process may seem complicated, the good news is that in most programming environments (sometimes called development environments), these steps are automated for you. Usually you will only have to write a program and type a single command to compile and run it. On the other hand, it is useful to know what the steps are that are happening in the background, so that if something goes wrong you can figure out what it is.
A program is a sequence of instructions that specifies how to perform a computation. The computation might be something mathematical, like solving a system of equations or finding the roots of a polynomial, but it can also be a symbolic computation, like searching and replacing text in a document or (strangely enough) compiling a program.
The instructions (or commands, or statements) look different in different programming languages, but there are a few basic functions that appear in just about every language:
Believe it or not, that's pretty much all there is to it. Every program you've ever used, no matter how complicated, is made up of functions that look more or less like these. Thus, one way to describe programming is the process of breaking a large, complex task up into smaller and smaller subtasks until eventually the subtasks are simple enough to be performed with one of these simple functions.
Programming is a complex process, and since it is done by human beings, it often leads to errors. For whimsical reasons, programming errors are called bugs and the process of tracking them down and correcting them is called debugging.
There are a few different kinds of errors that can occur in a program, and it is useful to distinguish between them in order to track them down more quickly.
The compiler can only translate a program if the program is syntactically correct; otherwise, the compilation fails and you will not be able to run your program. Syntax refers to the structure of your program and the rules about that structure.
For example, in English, a sentence must begin with a capital letter and end with a period. this sentence contains a syntax error. So does this one
For most readers, a few syntax errors are not a significant problem, which is why we can read the poetry of e e cummings without spewing error messages.
Compilers are not so forgiving. If there is a single syntax error anywhere in your program, the compiler will print an error message and quit, and you will not be able to run your program.
To make matters worse, there are more syntax rules in C++ than there are in English, and the error messages you get from the compiler are often not very helpful. During the first few weeks of your programming career, you will probably spend a lot of time tracking down syntax errors. As you gain experience, though, you will make fewer errors and find them faster.
The second type of error is a run-time error, so-called because the error does not appear until you run the program.
For the simple sorts of programs we will be writing for the next few weeks, run-time errors are rare, so it might be a little while before you encounter one.
The third type of error is the logical or semantic error. If there is a logical error in your program, it will compile and run successfully, in the sense that the computer will not generate any error messages, but it will not do the right thing. It will do something else. Specifically, it will do what you told it to do.
The problem is that the program you wrote is not the program you wanted to write. The meaning of the program (its semantics) is wrong. Identifying logical errors can be tricky, since it requires you to work backwards by looking at the output of the program and trying to figure out what it is doing.
One of the most important skills you should acquire from working with this book is debugging. Although it can be frustrating, debugging is one of the most intellectually rich, challenging, and interesting parts of programming.
In some ways debugging is like detective work. You are confronted with clues and you have to infer the processes and events that lead to the results you see.
Debugging is also like an experimental science. Once you have an idea what is going wrong, you modify your program and try again. If your hypothesis was correct, then you can predict the result of the modification, and you take a step closer to a working program. If your hypothesis was wrong, you have to come up with a new one. As Sherlock Holmes pointed out, "When you have eliminated the impossible, whatever remains, however improbable, must be the truth." (from A. Conan Doyle's The Sign of Four).
For some people, programming and debugging are the same thing. That is, programming is the process of gradually debugging a program until it does what you want. The idea is that you should always start with a working program that does something, and make small modifications, debugging them as you go, so that you always have a working program.
For example, Linux is an operating system that contains thousands of lines of code, but it started out as a simple program Linus Torvalds used to explore the Intel 80386 chip. According to Larry Greenfield, "One of Linus's earlier projects was a program that would switch between printing AAAA and BBBB. This later evolved to Linux" (from The Linux Users' Guide Beta Version 1).
In later chapters I will make more suggestions about debugging and other programming practices.
Natural languages are the languages that people speak, like English, Spanish, and French. They were not designed by people (although people try to impose some order on them); they evolved naturally.
Formal languages are languages that are designed by people for specific applications. For example, the notation that mathematicians use is a formal language that is particularly good at denoting relationships among numbers and symbols. Chemists use a formal language to represent the chemical structure of molecules. And most importantly:
Programming languages are formal languages that have been designed to express computations.
As I mentioned before, formal languages tend to have strict rules about syntax. For example, 3+3=6 is a syntactically correct mathematical statement, but 3=+6$ is not. Also, H2O is a syntactically correct chemical name, but 2Zz is not.
Syntax rules come in two flavors, pertaining to tokens and structure. Tokens are the basic elements of the language, like words and numbers and chemical elements. One of the problems with 3=+6$ is that $ is not a legal token in mathematics (at least as far as I know). Similarly, 2Zz is not legal because there is no element with the abbreviation Zz.
The second type of syntax error pertains to the structure of a statement; that is, the way the tokens are arranged. The statement 3=+6$ is structurally illegal, because you can't have a plus sign immediately after an equals sign. Similarly, molecular formulas have to have subscripts after the element name, not before.
When you read a sentence in English or a statement in a formal language, you have to figure out what the structure of the sentence is (although in a natural language you do this unconsciously). This process is called parsing.
For example, when you hear the sentence, "The other shoe fell," you understand that "the other shoe" is the subject and "fell" is the verb. Once you have parsed a sentence, you can figure out what it means, that is, the semantics of the sentence. Assuming that you know what a shoe is, and what it means to fall, you will understand the general implication of this sentence.
Although formal and natural languages have many features in common---tokens, structure, syntax and semantics---there are many differences.
People who grow up speaking a natural language (everyone) often have a hard time adjusting to formal languages. In some ways the difference between formal and natural language is like the difference between poetry and prose, but more so:
Here are some suggestions for reading programs (and other formal languages). First, remember that formal languages are much more dense than natural languages, so it takes longer to read them. Also, the structure is very important, so it is usually not a good idea to read from top to bottom, left to right. Instead, learn to parse the program in your head, identifying the tokens and interpreting the structure. Finally, remember that the details matter. Little things like spelling errors and bad punctuation, which you can get away with in natural languages, can make a big difference in a formal language.
Traditionally the first program people write in a new language is called "Hello, World." because all it does is print the words "Hello, World." In C++, this program looks like this:
#include <iostream.h>Some people judge the quality of a programming language by the simplicity of the "Hello, World." program. By this standard, C++ does reasonably well. Even so, this simple program contains several features that are hard to explain to beginning programmers. For now, we will ignore some of them, like the first line.
The second line begins with //, which indicates that it is a comment. A comment is a bit of English text that you can put in the middle of a program, usually to explain what the program does. When the compiler sees a //, it ignores everything from there until the end of the line.
In the third line, you can ignore the word void for now, but notice the word main. main is a special name that indicates the place in the program where execution begins. When the program runs, it starts by executing the first statement in main and it continues, in order, until it gets to the last statement, and then it quits.
There is no limit to the number of statements that can be in main, but the example contains only one. It is a basic output statement, meaning that it outputs or displays a message on the screen.
cout is a special object provided by the system to allow you to send output to the screen. The symbol << is an operator that you apply to cout and a string, and that causes the string to be displayed.
endl is a special symbol that represents the end of a line. When you send an endl to cout, it causes the cursor to move to the next line of the display. The next time you output something, the new text appears on the next line.
Like all statements, the output statement ends with a semi-colon (;).
There are a few other things you should notice about the syntax of this program. First, C++ uses squiggly-braces ({ and }) to group things together. In this case, the output statement is enclosed in squiggly-braces, indicating that it is inside the definition of main. Also, notice that the statement is indented, which helps to show visually which lines are inside the definition.
At this point it would be a good idea to sit down in front of a computer and compile and run this program. The details of how to do that depend on your programming environment, but from now on in this book I will assume that you know how to do it.
As I mentioned, the C++ compiler is a real stickler for syntax. If you make any errors when you type in the program, chances are that it will not compile successfully. For example, if you misspell iostream, you might get an error message like the following:
hello.cpp:1: oistream.h: No such file or directoryThere is a lot of information on this line, but it is presented in a dense format that is not easy to interpret. A more friendly compiler might say something like:
"On line 1 of the source code file named hello.cpp, you tried to include a header file named oistream.h. I didn't find anything with that name, but I did find something named iostream.h. Is that what you meant, by any chance?"
Unfortunately, few compilers are so accomodating. The compiler is not really very smart, and in most cases the error message you get will be only a hint about what is wrong. It will take some time to gain facility at interpreting compiler messages.
Nevertheless, the compiler can be a useful tool for learning the syntax rules of a language. Starting with a working program (like hello.cpp), modify it in various ways and see what happens. If you get an error message, try to remember what the message says and what caused it, so if you see it again in the future you will know what it means.
|
|
|
|
|