Text Processing: A Simple Pattern Matcher
The Motivation
In this project we develop a small and very fast pattern matcher modeled on some software we used in our newpaper's wire service programs to detect special sequences such as story headers and trailers. This was in our early typesetting system and, as in the spelling checker program, it was critical to keep the memory and CPU footprint as small as possible.
The original algorithm was written in assembler for the PDP-11 and only about 20 instructions long. Yet it could match multiple patterns in the input simultaneously even when these patterns were intersperced with each other. It could handle a surprisingly fast input stream
When we developed a new wire service program in the mid eighties, we kept the algorithm but converted it to C. This ran nearly as fast. I would like to demonstrate the algorithm first in Python first and then in two versions of C, one oriented around arrays and other using pointers. It is interesting to do some timing runs and see how Python stacks up to C and how C stacks up C optimized with pointers.
Let us watch the algorithm working before looking at the code. Here is a GIF animation where each new frame shows patterns being matched as each new character from the input is consumed. We're going to match for patterns stop, pit, and top. The very short input stream consists only of “stopit top”.
Animation. Return with the browser's Back button)
{kind=link}
When the program starts the patterns are loaded and it is ready to receive input. With the first character of input a “partial match” for the pattern “stop” is underway.

With the second character of input the match to “stop” is still active and a second possible match for “top” is started. Notice how the t*s in the partial matches line up with the last *t in the input.

But if the next character in the input is not what a partial match needs, the partial match is simply abandoned. Here is an example where a possible second match for “top” must be dropped with a “-” as the next input character.

Python Implementation
My hope is that seeing the above visualization will make understanding the algorithm and its immplementation quite straight-forward.
Let us start with the function main in patMatch.py (which you can save into a file to play with).
60 def main () :
61 pm = PatMatch()
62 text = sys.argv[1]
63 for pat in sys.argv[2:] : pm.addPattern(pat)
64
65 for ch in text :
66 pm.seeChar(ch)
67 sys.stdout.write('\033[1;1H\033[J\n') # clear screen
68 pm.dump() # produce animation frame
69 time.sleep(.5)
70 print "Done", len(pm.matches),"matches:"The pattern matcher is an object containing patterns and a working space. At Line 61 we create the pattern matcher and set pm to point to it. The first argument on the command line contains the text string where patterns will be found. The patterns themselves are subsequent arguments. (line 63). Then each character in the text is passed to the pattern matcher (line 66) and then a dump is printed (line 68) preceded by a strange print statement (line 67). This is a string which resets the cursor in a terminal window and then clears the window.
If the program is run in a linux terminal window like the following, the same pages (one per character of input text) will be printed on a cleared screen at half second intervals. Similar to what the GIF animation above produced. The last frame is displayed under the dots below.
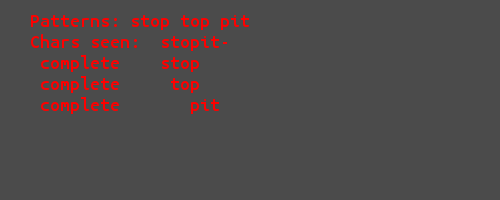
$ python patMatch.py "stopit-top" stop top pit
.
.
.
Patterns: stop top pit
Chars seen: stopit-top
complete stop
complete top
complete pit
complete top
partial pit
Done 4 matches:
$The PatMatch object contains the following attributes and methods.
01 #!/usr/local/bin/python
02 #
03 # p a t M a t c h . p y
04 #
05
06 import sys, time
07
08 class PatMatch :
09 def __init__ (self) :
10 self.patterns = [] # To match against
11 self.matches = [] # matches (pattern,nchar) found so far
12 self.working = [0]*50 # Partial matches
13 self.worktop = 0 # Limit for partials
14 self.chars = ""
15
16 def addPattern(self, pattern) :
17 # Add a pattern with its call back function
18 self.patterns.append(pattern)When the object is initialized, patterns are collected by addPattern into a string array (line 16). As matches are later found they are gathered in matches. The working area is a rather un-Pythonic set fixed length list of tuples that will be described shortly. worktop references the first available slot in working. chars are the characters scanned so far.
The main work is done is the method seeChar where the next input character ch is sent to be processed.
19
20 def seeChar (self,ch) :
21 # a new char to be handled
22 # if char starts a pattern - add it to top of workspace
23 pos = len(self.chars)
24 self.chars += ch
25 for p in self.patterns :
26 if ch == p[0][0] :
27 # partial match has pattern pointer and # chars matched
28 self.working[self.worktop] = (p, pos, 0, "partial")
29 self.worktop += 1
30
31 wp = wkeep = 0 # work-pointer, work-keepers
32 while wp < self.worktop :
33 # wpat is pattern, wcp chars matched so far
34 wpat,wpos,wcp,wsts = self.working[wp]
35 if wsts == "complete" : wkeep += 1 # leave in workspace
36 elif wpat[wcp] == ch :
37 # new character continues the match
38 wcp += 1
39 if wcp >= len(wpat) :
40 # Oh. the new char has completed match
41 self.matches.append((wpat,self.chars))
42 self.working[wkeep] = (wpat,wpos,wcp,"complete")
43 wkeep += 1
44 else :
45 # Still more to match. tuck partial match in
46 self.working[wkeep] = (wpat,wpos,wcp,"partial ")
47 wkeep += 1 # Adjust new worktop, keeping partial
48 else : pass # don't advance wkeep (drop failed partial)
49 wp += 1
50 self.worktop = wkeep # set worktop to matches keptIf ch starts any new pattern(s) then they pattern are loaded into available working slot (line 25-29). Then all partial matches are checked to see if the ch is compatible. The if statement (line 35) prunes the work area. Completed matches are kept but ignored. Partial matches compatible with ch are kept and perhaps completed. Partial matches incompatible with ch are discarded.
Discarding partial matches is done very efficiently. Partial matches that survive simply overwrite the discards and the work area is downsized accordingly. When a discard is copied over, it is only a pointer to a tuple that is copied; not the creation of a new one. Completion is a bit slower since the status element is updated to “complete”. It's all quite fast.
Finally, the method dump outputs a frame showing the state of the pattern matcher at any point.
52 def dump (self) :
53 print "Patterns: %s" % " ".join(self.patterns)
54 print "Chars seen: ", self.chars
55 for wp in range(self.worktop) :
56 wpat,wpos,wcp,wsts = self.working[wp]
57 space = " "*wpos
58 print " %-10s %s %s" % (wsts, space, wpat)Final Notes
Of course, used in a real setting things would look different. Obviously, there would be no dump between characters to slow things up. This is just for demonstration. The input might be a continuous data stream processed at a high rate. Patterns would likely be paired to call-back functions invoked whenever the pattern is matched. The effect might be something like switching tracks at a train yard directing the data stream to a different destinations or files.
If you have comments or suggestions You can email me at mail me
Copyright © 2014-2018 Chris Meyers
* * *